前言
看完本书学到很多东西,记此笔记和大家分享;考虑到本书内容庞杂,可以大致分为三部分:前六章是基础,之后的是具体平台fuzz的具体实现方式和注意事项,第三部分归类为其他。本次笔记谈的是前六章。
第一章 安全漏洞发现方法学
三种发现漏洞的方式
白盒测试、黑盒测试和灰盒测试是发现安全漏洞的三个主要方法。白盒要求测试者有被测系统的所有资源,黑盒则走向另一个极端,大部分情况属于“盲测”,灰盒在本书中讨论的方法是有编译后的二进制文件和部分基础文档。具体阐述如下:
白盒测试
- 进行代码评审(人工审计或上自动化);
- 优点:高覆盖(从理论上来说能发现一切漏洞);
- 缺点:太复杂也不太现实
黑盒测试
- 手工测试或fuzz(引出fuzz,简单地说是把程序非预期的数据都输入给被测应用,监视返回的结果);
- 优点:高可用(基本总是可用)、高可重现性(例如完成对某种服务器黑盒测试可以用相同原理用到类似的服务器上)、简单(无需了解细节,但是想发现有趣的问题也要深入学习);
- 缺点:黑盒测试不知何时停止、不知测试的效果、不聪明比较笨
灰盒测试
- 黑盒测试+逆向工程获得系统内部知识,通过反汇编器反编译器、调试器对应用进行深入剖析;
- 优点:能拿到二进制版本的被测软件后灰盒测试就能派上用场、覆盖率较黑盒有所增加;
- 缺点:复杂性,没有二进制成员参与逆向分析就寸步难行了
请记住三者没有优劣之分。

第二章 什么是模糊测试
模糊测试概念
学界最与之相近的术语是边界值分析,它是一种黑盒测试方法,其根据应用的合法和非法输入区间,选落在区间边界附近的值做输入。模糊测试已经和这个概念很相像,但区别是模糊测试并非仅关注边界值,还会关心任何能触发未定义或不安全行为的输入。
本书中模糊测试定义为:通过向应用提供非预期输入并监控输出的一场来发现软件异常的方法。其利用自动化或半自动化重复向应用提供输入。在此给出两类用于模糊测试的模糊测试器:
- 基于变异的模糊测试器(通过对已有的数据样本进行变异来创建测试用例);
- 基于生成的模糊测试器(为被测系统用的协议或是文件格式建模,基于模型生成输入并创建测试用例)
作者在这用了个形象的例子,例如我们的目的是破门进入一间房子,白盒测试就是我得到了房子任何信息,甚至知道卧室锁子的结构,但我只能看,不知道我真正要破门后发生什么;采用黑盒就能在夜晚悄悄在外部测试门和窗,向房子内窥找到最好突破口;选择模糊测试的话就只需选一个武器并使破门进房间成为自动化即可。
模糊测试历史
- 1989年,Miller教授用了一种原始模糊测试器测试UNIX的鲁棒性,思路是向应用中发送随机生成的字符串和字符;
- 1999年,Oulu大学创建PROTOS测试套件:通过分析协议规范来生成畸形的数据包;
- 2002年,微软向PROTOS提供资金支持,以继续发展(如实现了图形用户界面);
- 之后又有SPIKE模糊测试器被发布,该工具实现了基于块的方法用于测试基于网络的应用程序,有描述可变长数据块的能力,其还自带一个库,包含一些可能使应用发生故障的数据;同时该工具还有一些预定义的函数可以帮助生成常见的协议数据和格式数据。该工具在当时异常强大,支持了对Sun RPC和微软 RPC两种通信技术(值得一提的是发布SPIKE前,作者Aitel还发布了一个模糊测试器,它通过修改环境变量的值来发现漏洞,其采用了用共享库来hook返回环境变量的函数,返回的变量值比之前长的多来达到溢出目的);
- 2004年,mangleme工具生成大量不正常的HTML文件来发现Web浏览器漏洞,等等;
- 2004年,也是文件模糊测试兴起的一年,基于变异的模糊测试器大行其道;
- 2005年,一款硬件模糊测试工具把模糊测试潮流推向高潮;
- 2006年,ActiveX模糊测试开始流行;
- 。。。
模糊测试各个阶段
- 确定测试目标
- 确定潜在的模糊测试变量
- 生成模糊测试数据
- 执行!!!
- 监视异常
- 判断发现的洞是否能利用
目前存在的缺点
- 模糊测试器面对例如逻辑问题,设计问题这种层面更高的时候表现不佳;
- 不认识后门,因为模糊测试器觉得它和正常逻辑差不多;
- 内存被破坏后如果被测应用掩盖住模糊测试器就又不懂了;
- 测出有调用链的漏洞更加困难(人发现都困难更别说fuzz了)

第三章 模糊测试方法与模糊测试器类型
模糊测试方法
- 预生成测试用例(使用框架生成的测试列表,但用完了测试就结束了);
- 随机生成输入(效率低,但一些写的特别特别糟糕的代码仍会中招,但是找有效的测试值很困难);
- 手工协议变异测试(这时候人就是模糊测试器,输入不正确的数据使服务器崩,Sql注入是很好的例子);
- 变异或强制性测试(打乱有效样本的数据格式来实现自动化);
- 自动协议生成测试(分析应用,通过了解协议或文件定义的文法来生成模板,达到fuzz的目的,相当高级)
模糊测试器类型
- 本地模糊器(对本地应用的fuzz:有命令行直接fuzz,带有环境变量的fuzz,还有文件格式的fuzz);
- 远程模糊测试器(对在网络上打开端口的应用进行fuzz:有网络协议模糊测试器和对Web应用的模糊测试器);
- 内存模糊测试器:对进程拍快照,然后注入故障数据,测试完后恢复再重复注入;这种方法最大的优点就是如果协议进行了加密、校验或压缩算法,该测试器可以在上述算法完成后创建快照;然而缺点也存在,如有可能数据根本无法通过输入源输入,测试者想当然的注入进来就显得毫无意义,同时异常对应到输入源也很难确定;
- 模糊测试框架:即一个通用的框架,包含一个库生成测试字符串,此外还应包括类似脚本的语言,用来创建特定模糊测试器

第四章 数据表示和分析
什么是协议
协议在维基百科中被定义为在两台计算机端点间控制或使能连接,通信和数据传输的约定或标准。计算机间的通信也依赖于此,同时协议也有不同表现形式,比如便于人工阅读,有的人肉眼根本看不懂。协议中包含的各个部分被称为字段。
协议中的字段
- 变长字段(不为每个数据元素设定固定的长度对完全结构化、复杂的数据,最好用可变长字段,来提供灵活性)
- 定长字段(将每个字段长度设为固定值,最好的例子:TCP、UDP)
- 分隔字段(如简单文本协议用回车做分隔符)
常用协议元素
这块需要划重点,对此越了解,就月能够在fuzz中关注那些易于引发异常协议中的部分
- 名字-值对(如size=12,对值进行模糊可能会有奇效)
- 块标识符(用来标识二进制数据块的数据类型,文档中没有记录的块标识符很有可能接受额外的数据类型,意思就是捡漏)
- 块大小(通过修改块大小的值有可能能实现缓冲区溢出或下溢)
- 校验和(如果进行fuzz时破坏数据,却不修改校验和必然会影响读取应用,所以必须考虑)
可见对协议有一个好的理解会使得前期的工作事半功倍

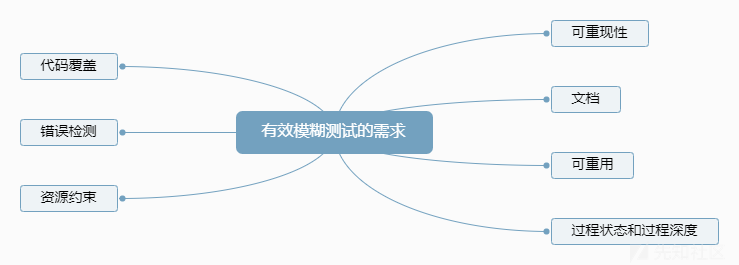
第五章 有效模糊测试的需求
几个需求如下:
- 可重现性:在每次运行时的被测应用行为应毫无二致,计算机没有绝对的随机;
- 文档:虽然不是必须的,但尽可能多的信息打包成清晰准确的形式绝对有利于分析和复现;
- 可重用:程序员不可能每fuzz一次就重写一个工具,复用组件是个好主意;
- 过程状态和过程深度:此概念可以理解为从家走到公司,走的每一步都是一次状态。过程状态就是目标进程在任意给定时刻所处的具体状态:如走了1步和走了10步,而过程深度时为了达到某特定状态所需要前进的步数的度量,我们走到公司旁的红绿灯和刚出门绝对不一样。这时要引出逻辑分离概念,概念就像出门走路的方向一样,往左走和右走可能会导致完全不同的fuzz结果;
- 代码覆盖:描述程式中源代码被测试的比例和程度,所得比例称为代码覆盖率。但是在作者写书时还没有哪项fuzz技术能够记录该指标;
- 错误检测:fuzz是“盲目的”,它们不知道被测应用对自己的反应,只能通过一些很“粗”的方式检查,例如程序是否被跑崩,能否ping通等,所以下一代有了调试客户端,进一步展望有可能二进制插装/翻译平台,该平台很底层,能有针对性的对被测目标进行分析插装;
- 资源约束:简单来说就是fuzz时候现实点(考虑周全)
第六章 自动化与数据生成
本章作者归到了“目标与自动化中”模块中,但感觉可以合并到基础中
自动化价值
- 程序员相较于之前的时间价值被提高
- fuzz什么人都能做(啊这)
- 同样的测试用例可能对不同服务器都产生效果
有用的工具和库
- Wireshark · Go Deep.
- libdisasm: x86 disassembler library (sourceforge.net)
- libdasm/README.txt at master · jtpereyda/libdasm (github.com)
- Libnet Documentation (sourceforge.net)
- TCPDUMP/LIBPCAP public repository
-
[metro packet library download SourceForge.net](https://sourceforge.net/projects/dotmetro/) - ptrace(2) - Linux manual page (man7.org)
- python 扩展:如Pcapy,Scapy和PyDbg
数据生成与模糊试探值
因为不可能穷举所有输入,所以输入用例必须有所突出
- 整数值:如0和0xFFFFFFFF,甚至0xFFFFFFFF-1、0xFFFFFFFF-2等对它的加减倍乘运算;
- 字符串重复:一堆“A”可能就会发生各种事;
- 字段分隔符:例如有时候分隔符起一个标志作用,程序扫不到会一直累加计数器进而引发溢出;
- 格式化字符串:这个就很严重了而且发现及其简单;
- 字符翻译:不合适的字符转换可能引发不正确的结果;
- 目录遍历:目录遍历修饰符也要被考虑;
- 命令注入:有时候我们的输入经过我们的构造可能会被执行,所以命令注入也得摆在突出位置
